後方互換性って辛いね、どうもかわしんです。
最近 Rust で SQLite をフルスクラッチで再実装しています。
再実装するために SQLite の公式ドキュメントやソースコードを読み込んでいるわけですが、その過程で気付いたおもしろポイントを共有しようかと思います。
今回はその第二弾、ファイルフォーマット編です。第一弾はこちら:SQLite のおもしろ仕様 (1) : データ型 - kawasin73のブログ
前提知識 : ページ
まず、この記事を面白いと思ってもらうための前提知識です。
大抵のデータベースはデータを保存するファイルをページという単位で管理します。SQLite ではデフォルトでは 1 ページ 4096 バイトです。これは、ファイルを保存するデバイス(HDD や SSD など)としてブロックデバイスを想定しているからです。ブロックデバイスとはデータの読み書きをブロック単位で行う、1 バイト単位のアクセスができないデバイスです。ブロックのサイズは 512 バイトだったりもっと大きかったりしますが、2 の冪乗のサイズです(例外があるかは知りません)。1 ページには 1 つ以上のブロックがピッタリ収まります。
多くのデータベースシステムでは I/O レイテンシーが支配的になるため、ディスクへのアクセスを最適化するためにページの境界を超えたデータの保存はしません。全てのデータアクセスの単位はページ内に収まるように設計されています。
可変長のデータの保存の仕方
第一弾 で紹介したように SQLite ではそれぞれのカラムにどの型のデータが来るかは実際に INSERT されるまでわかりませんし、同じカラムでも別の行では異なるデータ型になることもあります。つまり、ページ内に保存されるセルは全て可変長です。そのため、1 ページに何個のセルを保存できるかは動的に決まります。
SQLite のフォーマットではセルをページの後から先頭に向かって保存していき、それぞれのセルの先頭のオフセットをセルポインタとしてページの先頭から後ろに向かって保存していきます。
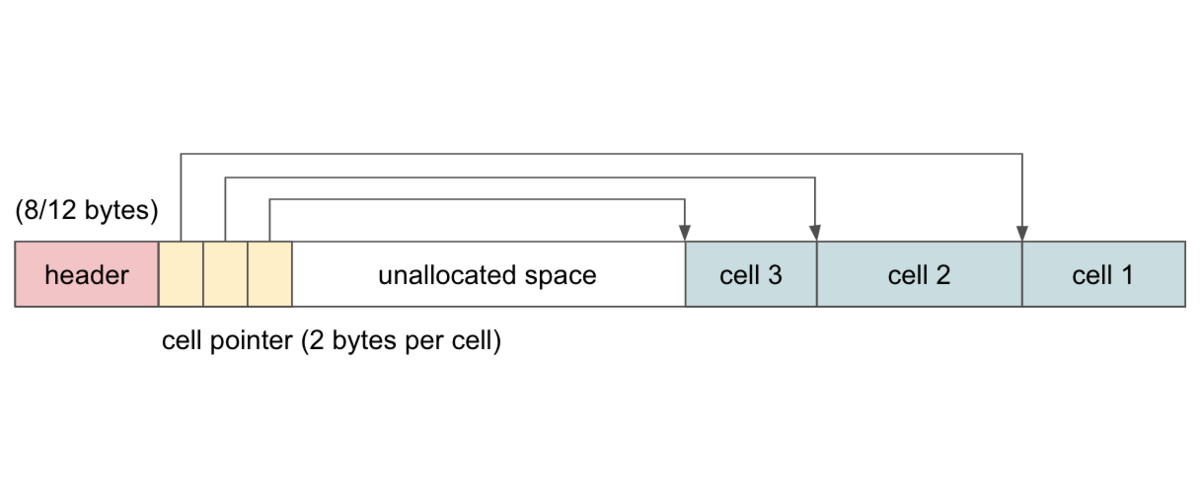
セルポインタは 2 バイトなので、X 番目のセルポインタの位置は一撃でわかり、ビッグエンディアンでエンコードされた値を読み取ればセルのオフセットも一撃で取得することができます。
もしセルサイズ + 2 バイトの余裕がそのページにない場合はそのページは満杯になったとして処理をします。
このシリアライズ方法は、可変長のデータをファイルに保存したいときとかに応用できそうです。
Overflow への対応
SQLite は、4096 バイトを超える文字列など 1 ページに収まらないような大きなデータの保存にももちろん対応しています。ある閾値を超えるサイズのデータは Cell Payload Overflow Pages に分割され、先頭のデータのみがセルとしてテーブルのページに保存されます。後続のはみ出たデータは Cell Payload Overflow Pages として連結リストの要領で複数ページに分割して保存されます。
さて、その閾値とセルとして保存されるバイト数は以下のように計算されます。
- X is
U-35for table btree leaf pages or((U-12)*64/255)-23for index pages.- M is always
((U-12)*32/255)-23.- Let K be
M+((P-M)%(U-4)).- If P<=X then all P bytes of payload are stored directly on the btree page without overflow.
- If P>X and K<=X then the first K bytes of P are stored on the btree page and the remaining P-K bytes are stored on overflow pages.
- If P>X and K>X then the first M bytes of P are stored on the btree page and the remaining P-M bytes are stored on overflow pages.
なんかぱっと見、複雑です。複雑なのは作者も認識しているようで、ドキュメントのすぐ下では後悔と負け惜しみが述べられていました。
In hindsight, the designer of the SQLite b-tree logic realized that these thresholds could have been made much simpler. However, the computations cannot be changed without resulting in an incompatible file format. And the current computations work well, even if they are a little complex.
(日本語訳): 振り返ってみると、SQLiteのBツリーロジックの設計者は、これらの閾値をもっとシンプルに設定できたと気づきました。しかし、計算方法を変更すると、ファイルフォーマットの互換性が失われるため、変更はできません。そして、現在の計算方法は、少々複雑であっても、うまく機能しています。
後方互換性って辛いね。
B 木 vs B+ 木
B 木とは 1 つのノードに 3 つ以上の値を保存する木構造です。ノードをページの単位に揃えることができるのでデータをブロックデバイスに保存するデータベースと相性がよく、データベースではデータ構造として B 木やその派生がよく使われます。
B+ 木は B 木の派生の一種です。B 木はそれぞれの値が重複せずに 1 つのノードだけに保存されている一方で、B+ 木は全ての値とキーの組を葉ノードのみに保存して検索のためのキーが中間ノードに重複して保存されているという特徴があります。B+ 木は中間ノードに値を保存しないため、より多くのキーと子ノードへのポインタを一つのノードに保存でき、木の階層を減らすことができます。また、葉ノード同士を繋ぐポインタを持つことで範囲検索時にアクセスするページ数を減らすことができるという利点もあるらしいのですが、SQLite では葉ノード同士を繋ぐということはしていませんでした。詳しくは自分で調べてみてください。
SQLite ではテーブルに B+ 木を、インデックスに B 木をと使い分けています。僕の推測ですがインデックスは巨大なサイズのキーを葉ノードと中間ノードに重複して保存するときの無駄が大きすぎるため B 木を使っているのだと思います。一方、テーブルのキーは 64 ビットの符号付整数を Varint エンコードしたものなので 1 ~ 9 バイトとサイズの上限が十分小さく、中間ノードに重複して保存したときの無駄は小さく済みます。
木の構造が微妙に違うので、SQLite の実装ではテーブルとインデックスで sqlite3BtreeTableMoveto() と sqlite3BtreeIndexMoveto() のように別々の関数が定義されています。一方でそれ以外の操作 (sqlite3BtreeInsert(), sqlite3BtreeNext() など) は共通の関数が提供されています。実装してみるとわかりますが、意外と共通の操作が多いです。
過去のバグの代償
Freelist はデータの削除などで使わなくなったページを再利用のためにリストするための構造です。
A bug in SQLite versions prior to 3.6.0 (2008-07-16) caused the database to be reported as corrupt if any of the last 6 entries in the freelist trunk page array contained non-zero values. Newer versions of SQLite do not have this problem. However, newer versions of SQLite still avoid using the last six entries in the freelist trunk page array in order that database files created by newer versions of SQLite can be read by older versions of SQLite.
(日本語訳): SQLiteの3.6.0 (2008-07-16)より前のバージョンでは、フリーリストのトランクページ配列の最後の6エントリのいずれかに非ゼロ値が含まれている場合、データベースが破損していると報告されるバグがありました。新しいバージョンのSQLiteにはこの問題はありません。しかし、新しいバージョンのSQLiteは、新しいバージョンのSQLiteで作成されたデータベースファイルが古いバージョンのSQLiteでも読み取れるように、フリーリストのトランクページ配列の最後の6エントリを使用しないようにしています。
3.6.0 より前のバグのために Freelist trunk page の最後の方の 24 バイトは未来永劫使われない領域になってしまいました。
後方互換性って辛いね。
ドキュメントされていない仕様
prsqlite は本家の SQLite と互換性を持つことを目標としているので、ドキュメントはもちろんですが本家のソースコードも読みながら実装しています。
そこで、どうやら 4 バイトより小さいセルは 4 バイトとして領域が確保されているらしいことがわかりました。これはドキュメントには書かれておらず衝撃でした。
static int balance_nonroot(
// ...
while( b.szCell[b.nCell]<4 ){
/* Do not allow any cells smaller than 4 bytes. If a smaller cell
** does exist, pad it with 0x00 bytes. */
static int freeSpace(MemPage *pPage, u16 iStart, u16 iSize){
// ...
assert( iSize>=4 ); /* Minimum cell size is 4 */
static int fillInCell(
// ...
if( n<4 ) n = 4;
僕の推測ですが、解放されたセルのサイズが 4 バイト未満だとページ内の freeblock list に追加できず "fragmented free bytes" として無視されてしまうため、なるべく解放されたセルを再利用させるための最適化なのだと思います。しかし、3 バイト未満のセルがあるファイルを SQLite が処理するとセルの解放時に別のセル領域を破壊してしまうため、これはドキュメントするべき仕様な気がします。
一方で、テーブルは最低 1 カラム以上、インデックスは最低 1 カラム + rowid の 1 integer 以上の要素が Record Format によってペイロードにシリアライズされるため、全てのセルは 4 バイト以上になるのですが、btree cursor 自体は Record Format とは独立であること、SQLite 自身が 3 バイトのセルのテスト をしている以上仕様っぽいです。
最後に
ファイルフォーマットは一度ファイルがユーザーの手元で作られてしまうと後方互換性を常に意識しながら拡張していかないといけないので、メモリレイアウトと比べてやり直しが効かず特に大変です。
こういう後方互換性を避けるためには、MessagePack とか Protocol Buffers とかのシリアライズフォーマットを使うとか SQLite などの組み込みデータベースを使うと安心です。しかし、部分更新をしたい場合とか、やりたいことに対して組み込みデータベースは複雑すぎる場合などは、自分でファイルフォーマットを考える必要があり(あった)、大変でありつつも楽しいですね。ハハハ。